Let θ represent the parameters of our neural network, and let τ represent a specific trajectory sampled from the probability distribution of all possible trajectories, denoted by pθ(τ). Our goal is to find the optimal parameter θ⋆ that maximize our expected value.
We define our objective function, J(θ), as the expected reward over these trajectories:
J(θ)=Eτ∼pθ(τ)[r(τ)].
To maximize this expected value, we need to find the gradient of J(θ) with respect to θ. We will show that this gradient can be expressed in a form that allows for estimation via Monte Carlo sampling.
Remark
A brief note on the notation τ∼pθ(τ):
The term pθ(τ) defines the probability distribution over all possible trajectories, parameterized by our network weights θ.
The variable τ refers to one specific, concrete trajectory.
The symbol ∼ means “is sampled from”.
In short, τ∼pθ(τ) means “A specific trajectory τ is sampled from the distribution of all possible trajectories defined by pθ.”
Calculating the Gradient of J(θ)
Because expected values represent a statistical average over a continuous space of trajectories, we can express J(θ) formally using an integral:
J(θ)=∫pθ(τ)r(τ)dτ.
We compute the gradient of J(θ) with respect to θ by taking the derivative of the integral. Assuming we can pass the gradient operator inside the integral, we see that:
∇θJ(θ)=∇θ(∫pθ(τ)r(τ)dτ)=∫∇θpθ(τ)r(τ)dτ
Remark
Note that ∇θ is an operator, not a variable. The expression ∇θJ(θ) should be interpreted as applying the gradient operator to J(θ), not as multiplying∇θ by J(θ).
To evaluate this integral numerically, one might initially consider Riemann sum. In a standard Riemann sum for an integral ∫f(x)dx, we evaluate the function at specific points and multiply by a small width Δx.
Applied to our trajectory space, we would slice the space of τ into small chunks Δτ, yielding:
n→∞limi=1∑n∇θpθ(τi)r(τi)Δτ
However, the space of possible trajectories is infinitely vast (encompassing all possible joint positions, velocities, and timestamps). Therefore, evaluating a Riemann sum over this space is computationally infeasible.
Monte Carlo Sampling
Because we cannot evaluate the integral analytically or via a Riemann sum, we turn to Monte Carlo sampling. To use Monte Carlo estimation, our integral must be structured as an expected value:
∫[Valid Probability Distribution]×[Some Value]dx
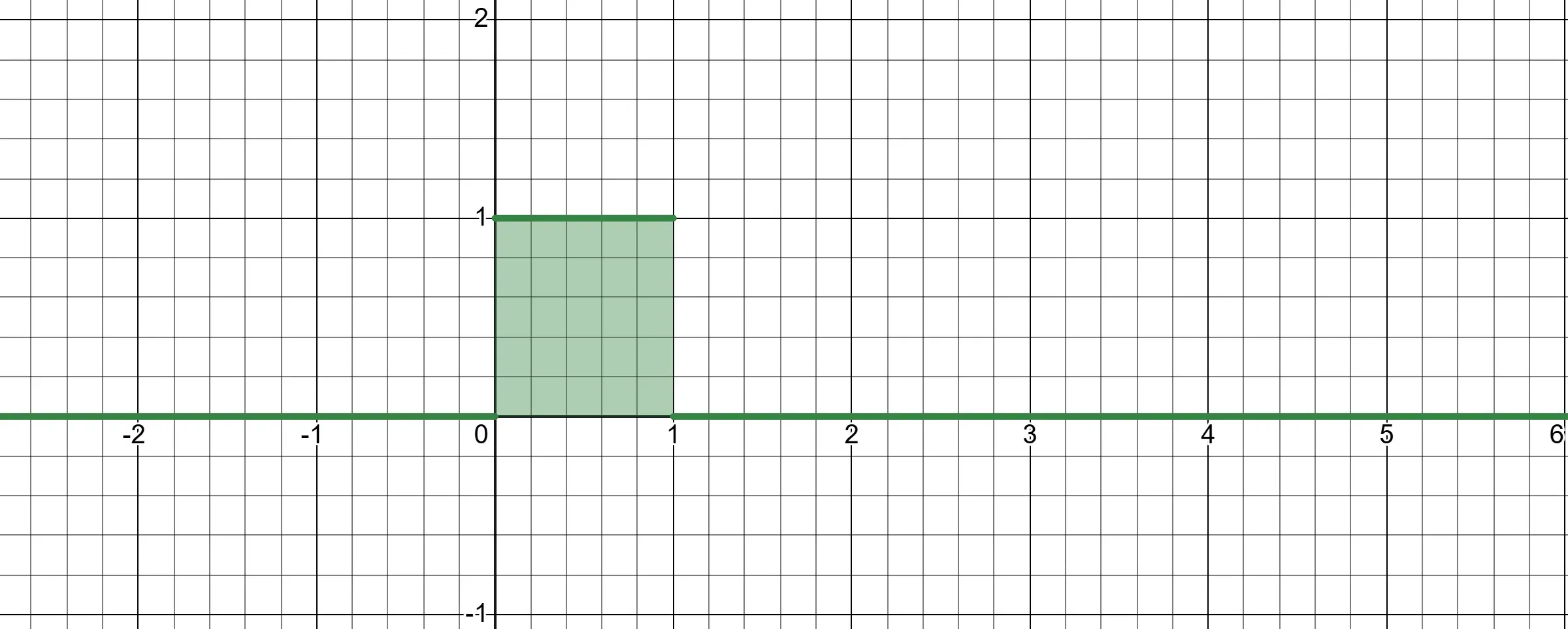
To illustrate, suppose we want to find the expected value of the function f(x)=x2, where x is uniformly distributed between 0 and 1. Here, our valid probability distribution is the probability density functionp(x)=1 for x∈[0,1], illustrated below.
Why is that
exactly a constant 1?
This brings us back to how is probability density function defined. A probability function satisfies p(−∞<x<∞)=∫−∞∞p(x)dx=1. The p(a≤x≤b)=∫abp(x)dx is one of the special case. In our scenario, the total area under the curve where 0≤x≤1 equals 1 which satisfies the 100% probability rule ∫01p(x)dx=1.
Formally, we write this expected value as:
Ex∼p(x)[x2]=∫01p(x)⋅x2dx.
Because p(x)=1, the exact analytical solution is:
∫011⋅x2dx=[3x3]01=31≈0.333.
If the function were too complex to integrate analytically, Monte Carlo sampling allows us to approximate the expected value by simulating it. We sample N random values from our distribution and average the results:
Ex∼p(x)[x2]≈N1i=1∑Nxi2.
Here is a brief Python script demonstrating this approximation:
import randomfrom collections.abc import Callabledef square(x: float) -> float: return x**2def uniform_sample(lower: float, upper: float) -> float: return random.uniform(lower, upper)def monte_carlo_sampling( sampler: Callable[[float, float], float], value: Callable[[float], float], sample_count: int,) -> float: total = 0.0 for _ in range(sample_count): x = sampler(0.0, 1.0) total += value(x) return total / sample_countprint(monte_carlo_sampling(uniform_sample, square, 1_000_000))
Running this code yields a result very close to 0.333, demonstrating the power of the Monte Carlo method.
The Log Derivative Trick
Returning to our policy gradient, we encounter a problem. Our current gradient expression is:
∇θJ(θ)=∫∇θpθ(τ)r(τ)dτ
This does not fit the Monte Carlo template because ∇θpθ(τ) is a gradient, not a valid probability distribution. To resolve this, we utilize a calculus identity known as the log-derivative trick.
Because the integral is now the product of a valid probability distribution (pθ(τ)) and a specific value (∇θlogpθ(τ)r(τ)), we can rewrite it as an expected value:
∇θJ(θ)=Eτ∼pθ(τ)[∇θlogpθ(τ)r(τ)].
Expanding the Probability of a Trajectory
Next, we must expand the logpθ(τ) term. The probability of a specific trajectory τ occurring is the product of the initial state probability and the probabilities of all subsequent actions and state transitions:
pθ(τ)=p(s1)t=1∏Tπθ(at∣st)p(st+1∣st,at).
Consider the the product rule of logarithm gives:
logb(xy)=logbx+logby,
we know that taking the natural logarithm of both sides transforms the products into sums:
Crucially, the terms p(s1) and p(st+1∣st,at) represent the dynamics of the environment. Because they do not depend on our network parameters θ, their gradients with respect to θ are zero. This allows us to cancel them out:
into logbx+logby? Proof
Assume for the sake of contradiction that it is viable to evaluate the objective without expanding the log, meaning we directly compute the log of trajectory probability pθ(τ)=p(s1)t=1∏Tπθ(at∣st)p(st+1∣st,at).
Let T be a large number of timesteps, such as T=500, and let the policy be confident, assigning a probability of 0.9 to each action. The trajectory probability will contain the product 0.9500, which is around 1.3×10−23. In a standard 32-bit floating point architecture, values like this cannot be represented and underflow to 0.0.
We have reached a contradiction, so our assumption was wrong. Therefore, we must expand the log. By doing so, the product transforms into a sum of logarithms: logpθ(τ)=logp(s1)+t=1∑Tlogπθ(at∣st)+t=1∑Tlogp(st+1∣st,at). This evaluates to a sum of manageable negative values, safely bypassing numerical underflow. ▪️
The Final Gradient of J(θ)
Finally, we substitute our expanded ∇θlogpθ(τ) expression and the expanded reward r(τ) back into our expected value equation.