As a robotics PhD student, I’ve been following LeRobot’s recent work on bimanual cloth folding, Unfolding Robotics: Open-Source Shirt Folding from Data to Deployment - a Hugging Face Space by lerobot. It serves as a manual for building real-world robotic systems. These are my notes.
I want this piece to do two things at once:
- Help readers who are new to robot learning enter the subject more easily.
- Provide minimal, actionable knowledge instead of a passive textbook summary, preserving the practical examples that actually changed how I think.
The ONE idea that stayed with me
If I had to keep only 1 lesson from this post, it would be this:
In robot learning, the biggest performance gap often does not come from inventing one more clever modeling trick. It comes from making the data cleaner, more consistent, and more intentional.
If you don’t believe me, feel free to read the original post. In the meanwhile, I don’t think it is a coincidence since in the same week the Generalist shares a similar perspective on Going Beyond World Models & VLAs.
Yes, it’s data, data, data, and still data!
Part 1: What the original post is saying
This part stays close to the authors’ main line of thought. I am trying to restate the post clearly.
1. The task is long-horizon, contact-rich, and dependent on real data
- Cloth folding is a difficult.
- Simulation is not yet reliable.
- Real-world reinforcement learning from scratch is inefficient.
There is only a way out: collect teleoperated demonstrations, then fine-tune a pretrained VLA.
2. Data collection is the longest and most important phase
Once again. Data. Data. Data!
3. Their recipe is straightforward
Their recipe fits the dominant VLA pattern today:
- Start from a pretrained VLA checkpoint
- Feed in images, joint states, and a language prompt
- Output chunks of actions
- Fine-tune on task-specific data
4. Evaluation is treated as seriously as training
One of my favorite lines in the post is: evaluation is as hard as training.
In other learning domains, you just run with torch.no_grad() on the test dataset. In robotics, real-world evaluation is slow, expensive, and noisy😤.
If the evaluation procedure shifts from experiment to experiment, then later comparisons is meaningless. So they deliberately fixed evaluation protocol.
That consistency is what makes later ablations believable.
5. TL;DR. Their Workflow and Tech Stack
Their article is quite length. If you just want a quick, actionable workflow, follow this order.
Part 2: Reader-friendly annotations and term explanations
This section is not trying to maximize formal precision. Its purpose is to help a first-time reader build usable intuition through examples.
1. What is a VLA?
VLA stands for Vision-Language-Action model.
A simple way to think about it is:
- Vision: what the robot sees
- Language: what the robot is asked to do
- Action: how the robot should move next
The architecture as an example
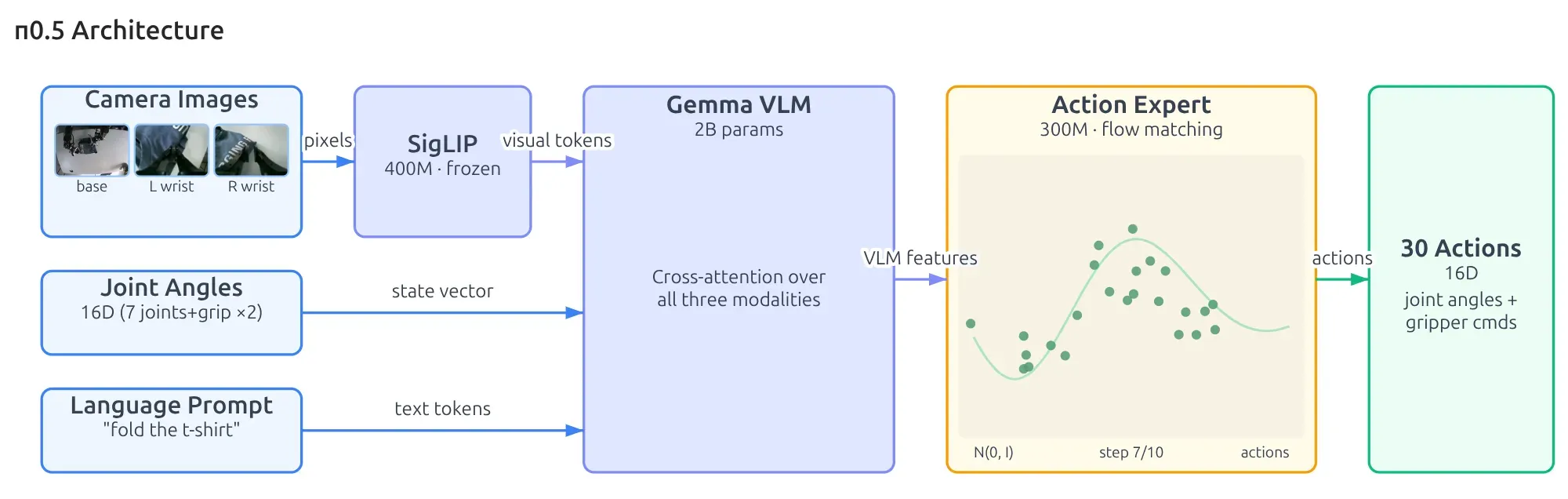
I think the diagram for this pi05 architecture is worth digesting. Let’s trace the data flow from left to right during inference:
- observation.images: the visual observation as pixels goes through SigLIP, resulting in a vector of numbers.
- observation.joint_states: this is the proprioception of the robot, and it is already a vector of numbers.
- language input: the format is a string, which goes through a tokenizer (I assume) to also become a vector of numbers.
- The preceding three inputs then go through a Gemma 3 VLM, resulting in VLM features. We can interpret these features as answering: What do I see? Where am I right now? What is my objective? - The VLM features feed into the action expert, which is essentially a Flow Matching denoising process. The Homework 1: Imitation Learning is a great example of this.
- Finally, we get an action chunking output, and its horizon spans 30 steps.
In short, a VLA tries to place scene understanding, task understanding, and action generation inside one pipeline.
The basic recipe in this post is simple and it is very common in practice.
- Take a VLA that has already seen a large amount of robotic interaction data
- Adapt it to your own task with task-specific demonstrations.
RemarkTwo common VLA models as of 2026-04-18:
- checkpoint
- GR00T checkpoint
2. What is action chunking?
Instead of predicting only one action at a time, the model predicts a short sequence of future actions all at once.
The intuition is:
- Motion becomes more continuous
- The model does not need to re-decide every tiny movement from scratch
- Long-horizon manipulation becomes easier to organize
But there is a practical tradeoff: inferring a whole chunk takes time. If inference is too slow, the robot pauses between chunks and motion becomes jerky.
RemarkSee my another post: Understanding Action Chunking with Flow Matching
3. What is RTC?
We know that the inference of an action chunk normally takes 100-200ms. If we do it synchronously, there are certain “void” between motions. The robot will stop there and wait for chunks derived to the next execution.
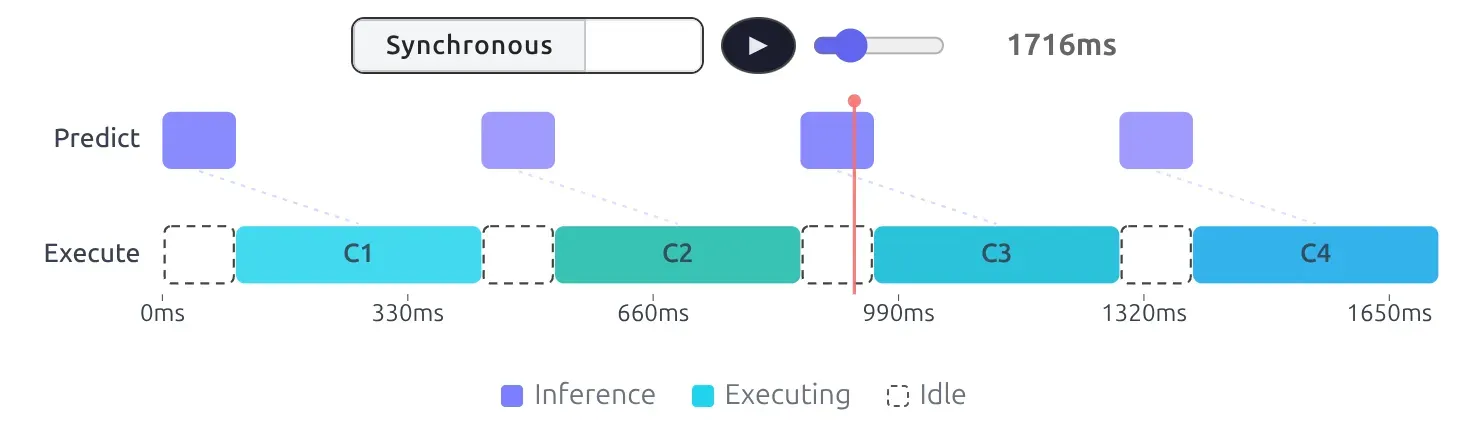
Notice the idle state where the robot just hangs, creating a jerky stop-and-move motion.
RTC was coined to solve this issue.
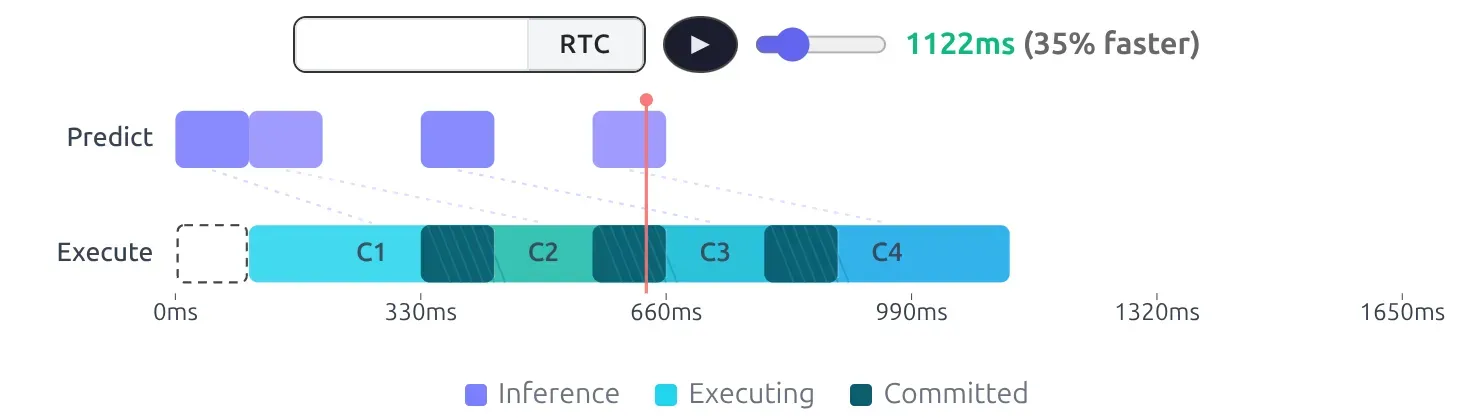
The idea behind RTC is to query the future action chunk while the robot is still executing its current chunk. As a result, RTC smooths that out by overlapping inference with execution.
4. What are relative actions?
A clean intuition is the model predicts not “where to go in absolute space,” but “how to move relative to the current state.”
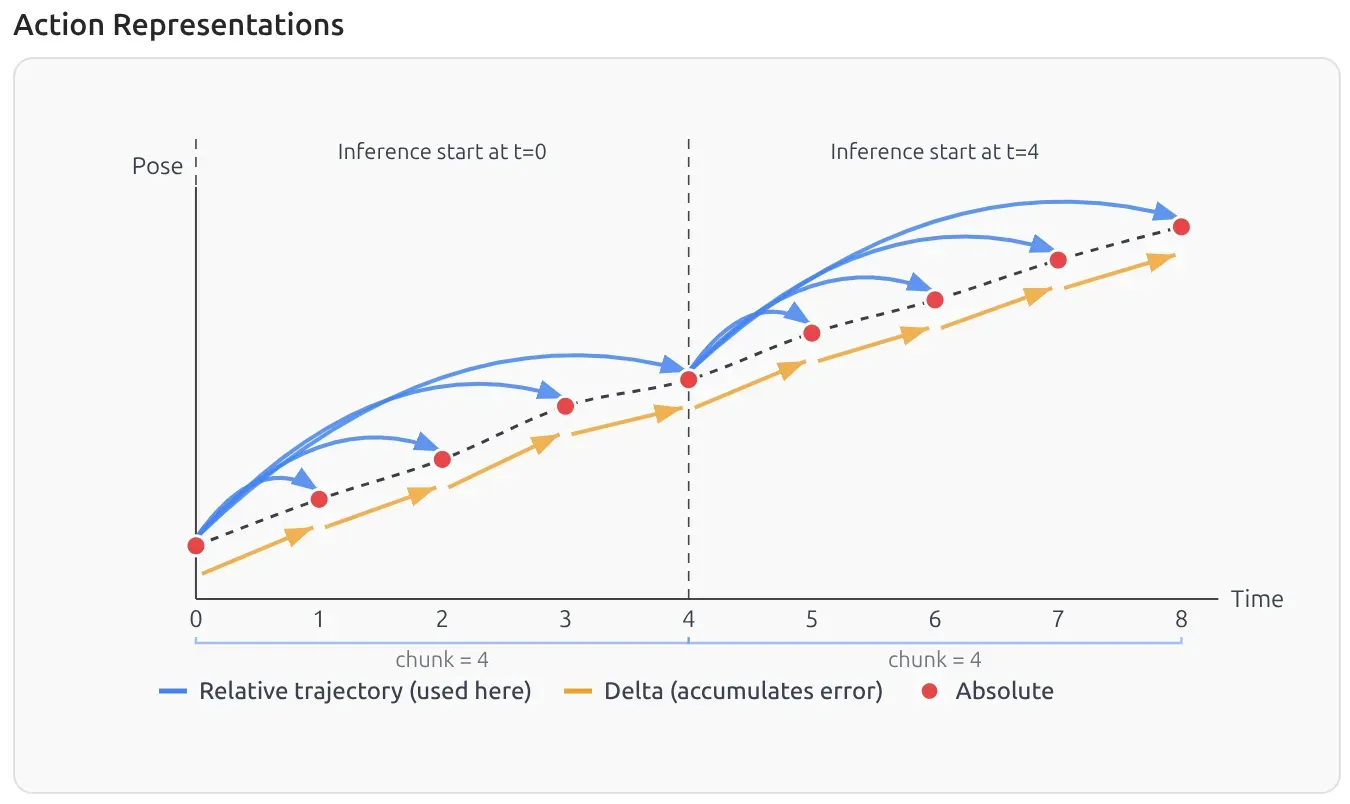
During inference, the output action is no longer an absolute joint position, but a “delta ” representing how much the end-effector should move respective to the current joint states. I think this is becoming the standard way to represent the action space, as it is the default in 📄GR00T N1: An Open Foundation Model for Generalist Humanoid Robots, ManiSkill, etc.
5. What is SARM?
A helpful first intuition is to think of SARM as a task progress scorer.
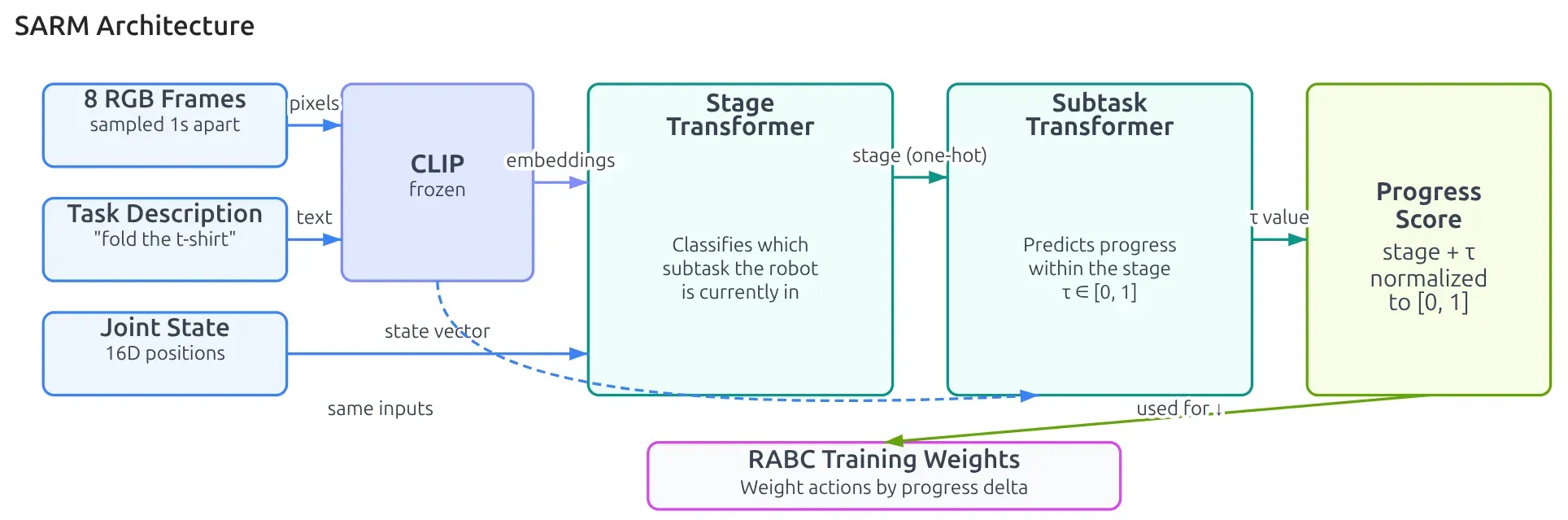
It addresses a real problem: 2 episodes may both succeed, but episode is finishes at 801st frame while episode finishes at 506th frame. How do you decide whether a given moment is
- still early on?
- already halfway through the task?
- close to completion?
SARM tries to learn a semantic notion of progress that is more meaningful than raw frame index.
In this post, SARM matters mainly because it helps with:
- data curation
- training-time reweighting
WarningOne clarification that matters.
The original SARM paper supports multi-stage structure. But in this LeRobot project, SARM is used in single-stage mode. In other words, they do not rely on a heavily hand-annotated multi-stage setup here. They treat folding as one continuous progress signal.
That distinction is worth keeping clear, because it is easy to mix up the general method with this specific engineering use case.
6. What is RABC?
The “RABC” refers to Reward-Aligned Behavior Cloning, a methodology introduced alongside SARM. A simple intuition for RABC is that not every action inside a demonstration deserves the same learning weight.
Standard behavior cloning often assumes every action equally contributes to finding the optimal weights for a policy .
RemarkSee my previous post: Why Naive Behavioral Cloning Doesn’t Work?
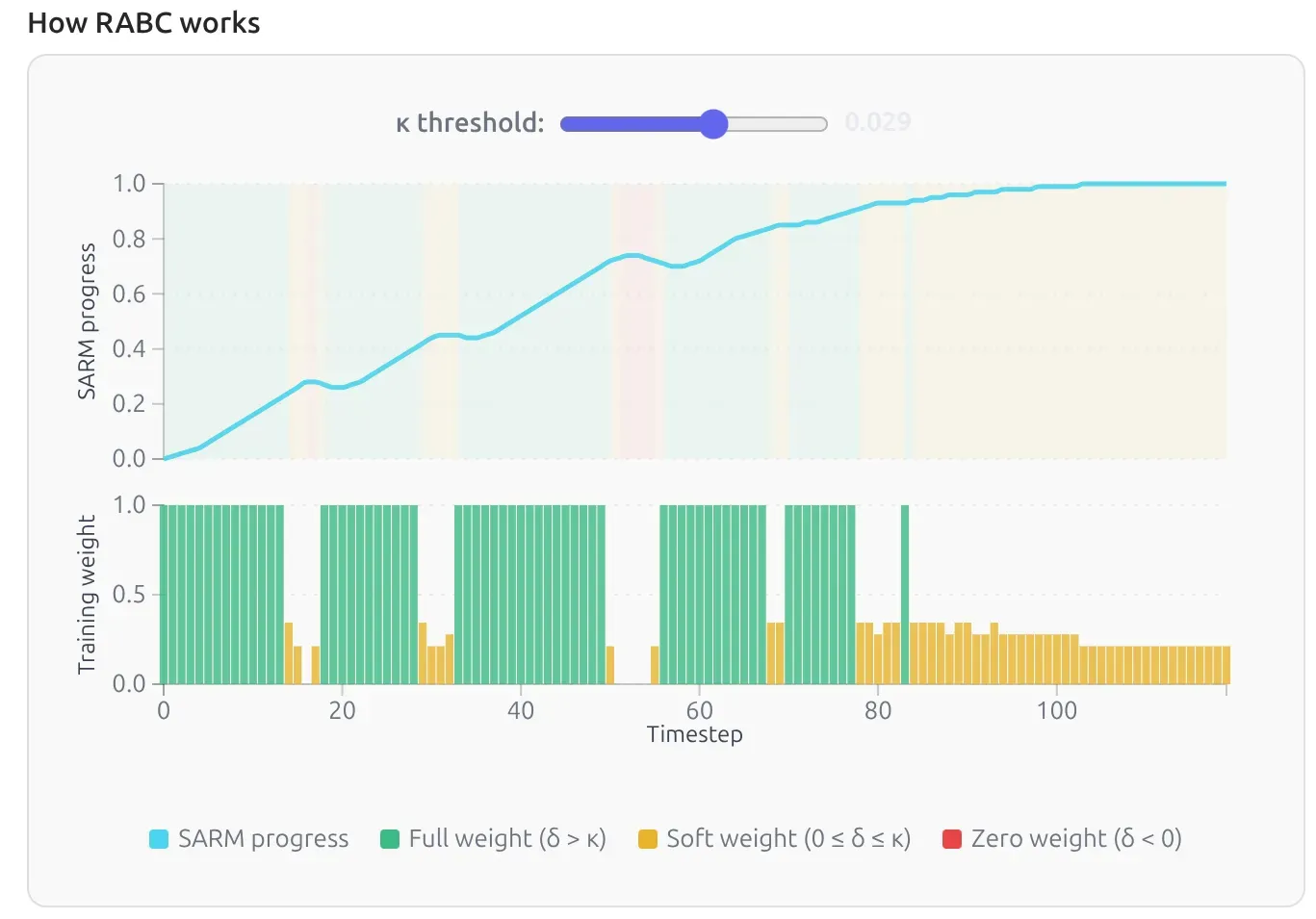
For example, see the three colors in the background of the progress bar:
- 🟩: good, progress advances
- 🟨: ok, stall
- 🟥: oopsi, progress regresses
The basic idea is:
- actions that advance the task get more weight
- actions that stall or regress get less weight, or none at all
This is why RABC pairs naturally with SARM. You first need a notion of progress before you can tell which actions are helping.
7. What is DAgger?
The easiest way to remember DAgger is do not collect data only from ideal states; also collect the recoveries a human demonstrates when the policy begins to fail.
I first heard of DAGGER is from Sergey Levine’s CS 185/285: Deep Reinforcement Learning where he introduced the paper 📄A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning as a solution for the pitfalls of naive behavior cloning. The idea is simple and effective. The downside is that it requires active human effort for augmentation.
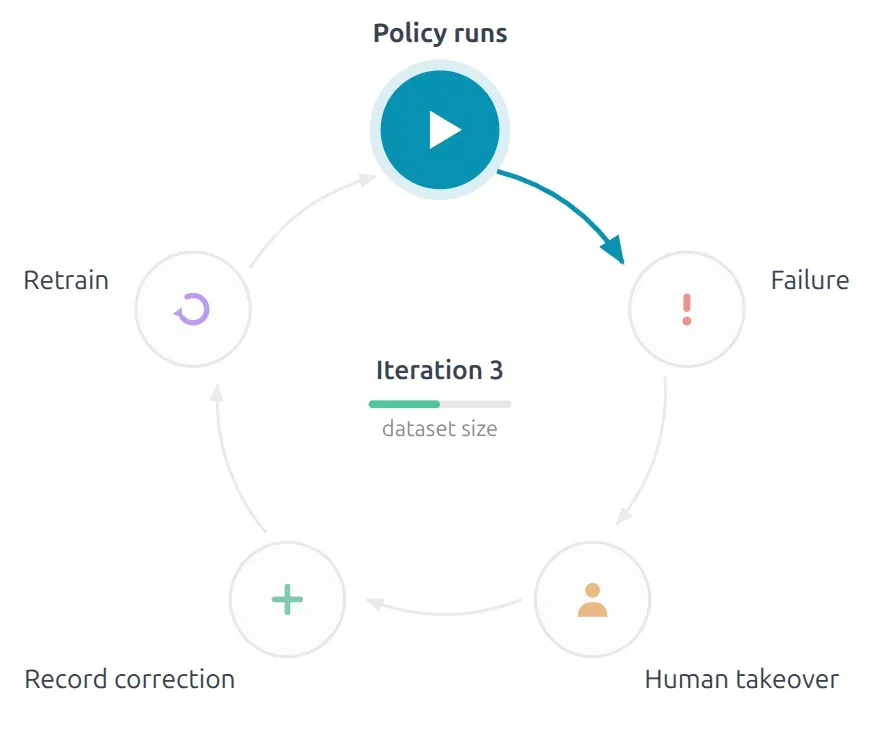
Let’s appreciate how the LeRobot team made the augmentation easier. I consider this to be incredibly innovative engineering.
RemarkI found out the term “engineering” is sometimes used as a derogatory term in academic circles. I personally don’t buy into this nonsense. Ideas are cheap; show me the code. Without this tremendous engineering work, how could anyone enjoy implementing algorithm?
Keyboard Controls:
SPACE - Pause policy (robot holds position, no recording)
c - Take control (start correction, recording resumes)
p - Resume policy after pause/correction (recording continues)
→ - End episode (save and continue to next)
← - Re-record episode
ESC - Stop recording and push dataset to hub
You don’t need to implement these features from scratch. Here is their Human-in-the-Loop infrastructure.
8. Why Mirror Augmentation didn’t work
The team wanted to double the size of their dataset via data augmentation by mirroring the data. It didn’t work. My intuition on this relates to probability distribution. I think mirror augmentation might work for asymmetric target points. For example, the action trajectory needed to reach a t-shirt sleeve at [-5, 0] is different for the left arm versus the right arm (augmented).
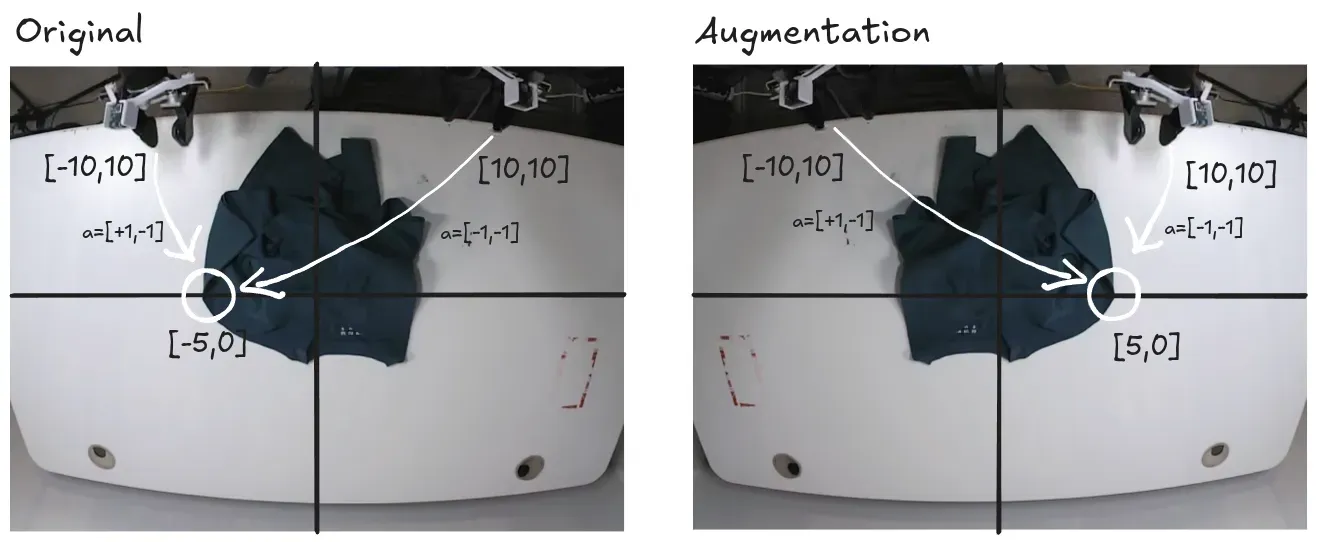
But what if you want to reach a symmetric point, say [0, 0]?

The probability distribution to reach the same central target might be perfectly even. But that is just my intuition. Recalling what I learned about Flow Matching, it serves as a solution to solve a mixture of Gaussians. This “even” distribution shouldn’t theoretically be an obstacle. Yet, the LeRobot team explicitly states it doesn’t work. Could it be related to the high-dimensional space? I’ll leave this question as a puzzle for my future self.